| 2017-11-09
我们原来是怎么工作的
2014年9月,我们已经进入了云计算的第三个年头。然而,我们当时仍旧是按照云计算时代之前的那种传统方式进行测试。
我们试图更快地完成任务,试图优化自动化测试,但我们一直在挣扎。
运行自动化测试需要花太长的时间,而且经常失败
我们的自动化测试用例集,运行的时间太久了。我们有一个名为NAR的测试套件,它表示夜间自动化运行(Nightly Automation Run)。这个自动化测试套件要花22个小时,也就是告诉我们的工程师,这个测试套件要运行一整晚。有趣的是,我们还有另一个测试套件叫做FAR,就是Full Automation Run,这个测试套件运行一次,需要两天的时间。回想起来,我们那样命名测试套件看起来很荒谬,但这就是我们曾经引为骄傲的状态。
自动化测试用例经常失败。每次运行都会有大量的失败用例,完全做不到全部成功通过。而在失败用例中去筛选和鉴别哪些是真正的失败又是如此耗时,以至于团队在迭代(sprint)结束之前,都是完全忽略这些失败用例的。回想起来,我们可能从一开始,就从来没有过对产品进行过一次完整的测试,能够达到100%的通过率。
我们专注于提高P0用例的运行可靠性——大约有几十个集成测试。让这些用例一直保持能够通过是件非常痛苦的事。我们会在一个严密的环境中运行它们,并计算它们100%通过的频率。如果它们失败了,我们会提交一个P0用例错误并督促团队修复它。我们齐心协力地努力让这些P0用例集能100%通过,但也只有70%左右的时间达成了这个目的。它们会以各种方式失败:基础设施、产品问题、测试中的缺陷。
我们根本不能相信,对Master分支代码进行验证后所发出的质量反馈信号。工程师将代码更改提交给master,然后在12小时后,可以得到包含一系列失败用例的第一个质量反馈信号。他要花很长时间才能从那些失败用例中筛选出来有用的失败信号。因此,迭代临近结束之前,团队的习惯是忽略这些失败用例。在迭代临近结束之时,我们需要花费很多精力才能发布这个迭代的工作。有时候,我们压根花上三个多星期的时间才发布。
新的质量愿景
很明显,我们需要一种全新的方法。2015年2月,我们发布了新的Azure DevOps质量愿景文档。 这个愿景的核心部分是从头开始,重新整合我们的整个测试套件。我们首先构造了一个“我们所希望的整个测试套件应该长什么样”的蓝图,如下图所示。虽然 Y 轴没有具体的数字,但我们用相对的比例来说明这一点。L0,l1是单元测试,L2,l3是功能测试。
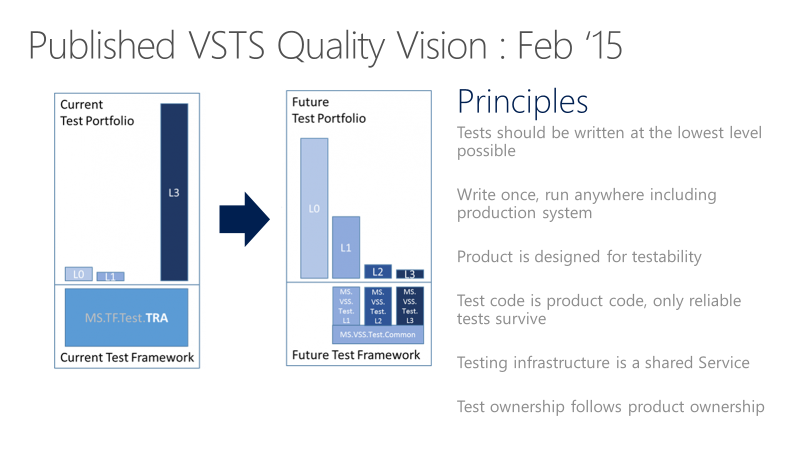
测试原则
我们建立了一整套团队应该遵守的原则,这些原则基本上是可以无须更多解释的。
测试用例应该尽可能在最低的级别写。
Tests should be written at the lowest level possible
这是一种说法,与所有其他类型的自动化测试相比,我们更喜欢具有最少外部依赖的测试用例。我们希望将来的大多数测试都作为构建的一部分来运行。设想一个并行构建系统,一旦程序代码本身和相关联的测试程序集被修改,该系统都可以立即运行该程序集的单元测试。显然,我们不能在这个级别保证能够测试到应用服务的每一个方面,但我们需要记住的原则是,如果单元测试(L0)可以对被测的东西提供相同的信息,我们决不应该选择使用功能测试(L2/L3)。
编写一次,随处运行,包括生产环境
我们原来的测试组合中,大量的测试用例都依赖于我们自己构建的一个测试服务器,即Object Model。产生这种情况的原因很多,包括产品代码本身缺乏可测试性。这种实践应该被终止使用,原因有如下几个:(1)写入到OM服务器的测试用例依赖于这个服务的一些内部知识,而且从功能测试的角度来说,暴露了太多的代码实现细节,而事实上,这些细节在测试用例中常常是不必要的。(2)它还将测试用例绑定到了运行它们的环境上,因为只有这些环境有它们所需的一些小秘密和配置信息。这就使得这些功能测试用例无法针对生产环境上运行。让我们换一种说法来陈述这个原则:功能测试(L2/L3)应该只使用产品提供的公共API,而不是程序后门。
在软件设计时必须考虑可测试性
在这种多角色组合的工程模型下,我们拥有了一个非常关键机会,那就是可以更好地全面了解在云计算节奏下交付高质量产品意味着什么。将测试的天平强烈地倾斜向单元测试(L0)而不是功能测试(L2/L3),这需要我们对我们所开发的产品进行可测试性的设计和实现。从可测试性的角度来看,关于什么构成了设计良好、实现良好的代码,存在着不同的思想流派,正如对编码风格有不同的看法一样。但要明确记住的原则是:面向可测试性进行设计必须成为整个团队关于设计和代码质量的讨论的首要部分。
测试代码也是生产代码,只有可依赖的测试代码才能存活
这说明:我们对待测试代码时,需要有对待产品代码一样的心态。有时我们说“ Config is Code ”,其实就是在说,配置数据的管理也应该和产品代码有同样高的重要性。明确说明“测试代码就是产品代码”这一原则,是为了说明测试代码的质量水平与产品代码一样重要。我们必须在测试用例和测试框架的设计和实现中应用同样的谨慎。在代码评审( Code Review )中不审查测试代码或将对测试代码降低要求,就不是一次完整的代码评审。
在组织层面上,一个不可靠的测试用例其成本是非常昂贵的。它直接违背了提升工程师效率的目标,让工程师难以非常自信地对代码做出变更。我们希望达到这样一个水平,即:工程师可以随时随地进行代码变更,并且能够迅速获得高度的信心,即:没有任何东西因为这次变更而被破坏了。我们必须保持很高的可靠性标准。我们不鼓励使用UI测试。糨作为自动化测试的一个类别,我们的经验是它通常是不可靠的。
测试基础设施是一个共享的服务
我们必须降低用我们的测试基础设施生成可信任的质量反馈信号的门槛。单元测试(L0)代码要与产品代码在一起,并且应该与产品一起构建。我们最终希望这些测试能作为构建过程的一部分运行。这些测试还必须在Visual Studio Team Explorer下运行。测试是整个团队的共享服务,并得到很好的支持。它要像产品代码一样的可靠性。
测试的所有权应该与产品的所有权保持一致
最后一点是:测试的所有权应该与产品保持一致。换句话说, 测试就应该在产品代码旁边。如何你负责一个组件,你不应该依赖别人来测试你的组件。我们把责任推给那个编写生产代码的人。
测试左移!
这是通过一条管线所看到的质量愿景的另一种说法,它展示了向左移动并将质量提升到上游意味着什么。大多数测试甚至在变更合并到主干(master)之前就已经完成。
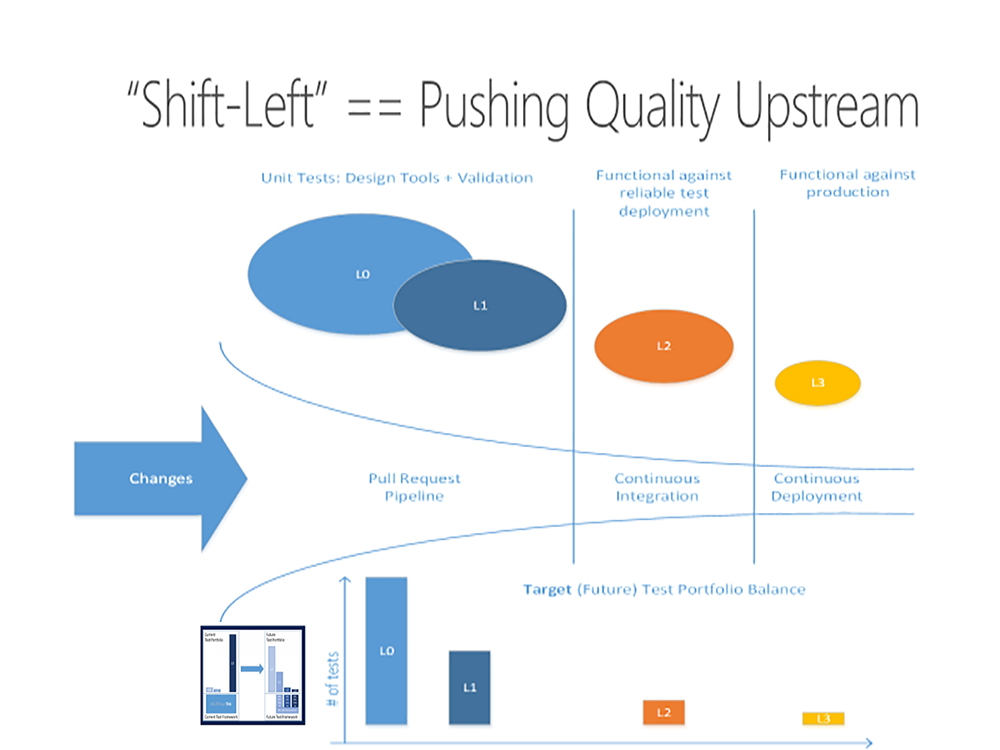
要把愿景推销给团队
我们必须解决的第一个问题是说服团队开始编写更多的单元测试。以前,大部分测试用例都是由专职测试人员编写的。以前,单元测试的“肌肉”并没有发育过。所以,对这一战略有着彻底的怀疑。单元测试战争爆发了。产品真的可以这样测试吗?我们以前在单元测试方面有过不好的经验——这次有什么不同么?管理层会致力于这一愿景吗?你可以看到这里的拉锯战,那里有人极度怀疑,不仅对方法,而且对背后的管理承诺。还有一些人对这个新方向充满热情。我们对允许的单元测试类型进行了激烈的辩论,经典方法和Mock方法,换句话说,就是完全隔离的单元测试和需要一定程度依赖的单元测试。
对于每一个问题,我们都采取了相当务实的方法,并专注于让飞轮运转起来。例如,对于可能进行重构的代码或者是新代码,我们提倡使用经典单元测试方法。但是,在为遗留代码库编写单元测试时,我们允许使用一些依赖。我们的产品代码的很大一部分使用SQL,我们允许单元测试依赖于SQL资源提供者,而不是模仿这个SQL层。

对测试进行重新分类
我们需要对测试定义新的分类方法。以前的分类法是基于测试的持续时间、夜间运行(NAR)、完全自动化运行(FAR)等。我们创建了新的基于外部依赖性度量的分类法。我们把测试大致分为两类。
L0/L1 – 单元测试
L0 – 广泛使用的快速且仅依赖内存的单元测试。一个 L0 级的测试对大多数人来说,就是一个单元测试,这个测试只依赖于在被测单元所构建的代码,没有别的依赖。(That is a test that depends on code in the assembly under test and nothing else.)
L1 – 一个 L1级的测试可能依赖于程序本身加SQL或文件系统。
L2/L3 – 功能测试
L2 – 这个级别的功能测试是在“可测试”的服务部署之上运行的。它属于功能测试类别,需要服务部署,但可能以某种方式将关键的服务依赖关系断开。
L3 – 这个级别的测试是严格意义上的集成测试,运行于生产环境之上。它通常需要整个产品的部署才行。
单元测试具有的特征
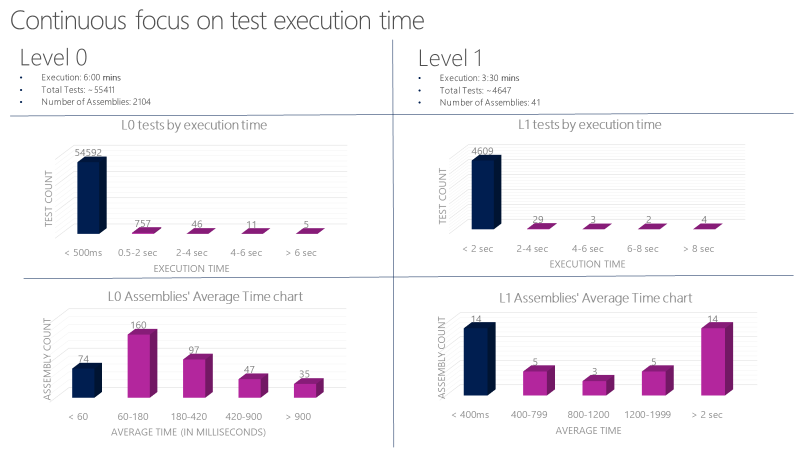
对于L0 和 L1 的单元测试,我们有严格的指导手册。这些测试的运行要非常快且非常可靠。L0级别的测试平均每个测试的运行时间要少于 60ms,而L1级别的测试,平均每个运行时间小于400 ms,这一级别的测试用例,运行时间不允许超过2秒。目前(2017年),我们可以在 6分钟之内并行执行完成6000多个单元测试,我们的目标是少于1分钟。我们使用下面的图表来跟踪单元测试的执行时间,如果超过时间阈值,就会自动登记一个Bug。
功能测试必须独立
对于L2级别的测试,其关键在于“测试隔离”。做了正确隔离的测试用例就可以按任何顺序可靠地执行,因为它完全可以控制它所运行的环境,不受外界影响。在测试用例运行之前,环境必须处于一个完全受控且已知的状态。如果一个测试用例运行时在数据库中增加了一条数据,并且在运行结束时没有清理它,那就有可能影响后续一个依赖于数据库不同状态的测试用例的执行。
在我们旧的功能测试用例中,如果一个测试用例需要一个用户ID,它会调用一个外部的 authentication providers 来得到一个ID。这种做法有几个非常大的问题。首先,这个外部依赖项可能很脆弱,甚至有时无法正常提供服务,这就会导致这个测试用例失败。这违反了测试用例的独立原则,因为该用户的身份(比如权限)被某个测试用例更改过了,但是下一个测试用例仍旧期望使用原来的身份,结果就会失败。
为了规避这种情况,我们在核心测试框架中构建了一个假的身份支持模块。它使用核心平台的可扩展性与产品保持一致。L2测试可以利用这些身份并完全隔离地运行测试。决定在产品的哪个位置使用这个替身,需要非常谨慎。
设置一个北极星指标,且衡量每个迭代的进展
下图是我们以三星期为迭代周期的进展表。这个表是从第78个迭代到第120个迭代,也就是42个迭代或者126个星期,大约两年半的成果。
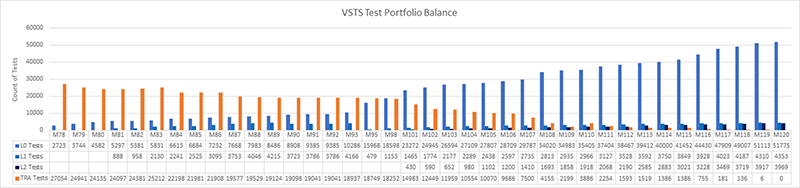
在第78个迭代,我们有27000多个遗留的自动化测试用例(橙色)。大多数老的功能测试被L0和L1级单元测试所取代。有一些被新的L2级别的测试用例所取代。而很多都直接删除了。任务完成!整个新的测试套件看上去比我们前面设置的那个愿景图还要好。
让我们谈谈我们是如何完成这次蜕变的。当我们开始时,我们把旧的功能测试(“TRA测试”)放在一边没管。首先,我们想让团队认同编写单元测试的想法,尤其是针对新特性的单元测试。我们想让飞轮运转起来。我们让编写L0和L1测试变得非常容易。我们想先锻炼肌肉。该图显示单元测试计数在早期就开始累积。团队开始看到编写单元测试的好处。这些测试更容易维护,运行速度更快,失败次数更少。我们开始运行PR中的所有单元测试(PR是指pull request)。
直到第101个迭代开始,我们才聚焦于L2级别的测试。同时,TRA 测试用例的数量从第78个迭代的27000多个下降到了第101个迭代的14000多个。有一些TRA测试被新的单元测试所取代,但有一些是直接被删除了,因为根据团队的分析,那些自动化测试本身也没用。值得注意的是TRA测试在第110个迭代是如何从2100个用例一下子提高到了3800个。我们并没有写新的TRA测试。我们只是在代码库中找到了更多的TRA测试,并把它们加入到了这个图表中。我们会运行这些测试,但并没有跟踪它们。
总的来说,在过去2年多的时间里,完全重写了我们所有的自动化测试,这是一项巨大的投资。每一个迭代,整个组织中的很多特性团队都在这方面投入了时间。在某些迭代中,它可能是某个特性团队的最主要工作内容。当然,并不是每个小组都是在同一时间做这项工作的。我们并不知道这样做的总成本是多少。但是,如果不这样做,我们就无法实现我们的目标。所以从长远来看是值得的。
快起来了
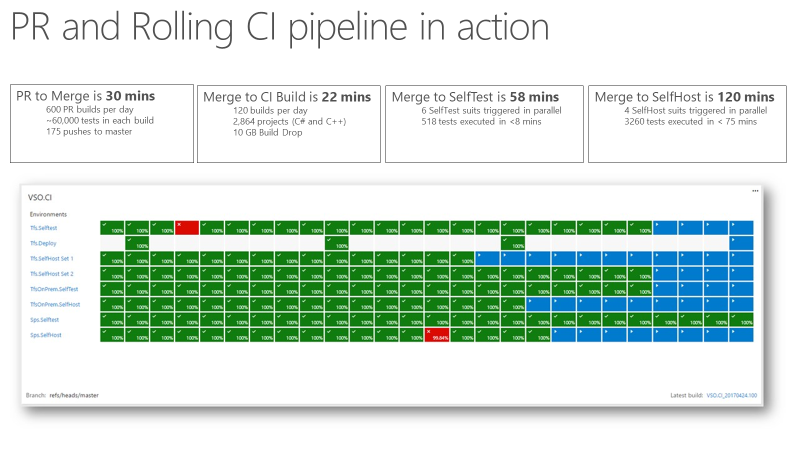
在这里,一个关键点是:一旦你有了一个可靠且极快速的持续集成反馈信息,你就可以信任你的CI信号了。下面的图片显示了我们的PR和CI流水线的运作情况,以及通过各个阶段所需的时间。从PR到Merge需要大约30分钟。我们在Pull Request时运行了大约60000个单元测试。从代码的合入到CI构建大约需要22分钟。从CI(自检)得到的第一个质量反馈信号大约需要一个小时。那时,产品的大部分都会包含这个变更的测试。在2小时内(从Merge到SelfHost),整个产品就完成了测试,变更的代码就准备好部署到生产环境中了。
我们用的DevOps度量
这就是我们的团队记分卡。在顶层设计上,我们跟踪两种类型的度量:生产环境与工程健康(或债务),以及工程速度。

对于生产环境,我们关心一个团队引入问题后,需要多长时间才能被发现,需要多长时间才能减轻影响。一个修复工单多长时间才能上线完成。一个修复工单是指团队在生产复盘总结中识别出来的防止再次发生同类事件的一个工作项。我们会跟踪该团队要在合理的时间内关闭这些维修工单。
对于工程健康,我们会记录每个工程师手上还未修复的缺陷数。如果一个团队平均每个工程师手上有5个以上的缺陷,他们就必须在开发新特性前优先修复这些缺陷。我们还跟踪特殊类别中存在时间比较长且没有被修复的缺陷,如安全性类。 对于工程速度,我们衡量CI/CD流水线不同部分的速度,总体目标是提高从一个想法开始到将代码输出到生产环境以及从客户那里获取数据的速度。
原文链接: