| 2022-03-26
当测试用例现在失败,而它之前是执行成功的,这是一个强烈的信号,表明代码出现了新的问题。
之前,测试通过了,而且代码是正确的;
现在测试失败了,代码运行不正常。
一个好的测试套件的目标是使这个信号尽可能清晰和有针对性。
然而,不稳定(不确定性, nondeterministic )测试用例则不同。不稳定测试用例( Flaky tests )是使用同一代码运行测试时,即成功过,也失败过的测试用例。
有鉴于此,测试用例失败可能意味着出现新问题,也可能不意味着出现新问题。
通过使用相同版本的代码重新运行测试用例,结果可能会成功,也可能会失败。
如果真是这样的话,我们开始认为这些测试不可靠,最终它们也失去了价值。
假如失败的根本原因是生产代码中的不确定性,那么忽略这些测试结果也就意味着忽略生产缺陷。
谷歌的不稳定测试
谷歌在我们的持续集成系统上运行了大约 420 万个测试用例。其中,约有 6.3 万个在一周的时间里有一次不稳定。虽然这在我们的测试中只占不到 2 % ,但它仍然会对我们的工程师造成很大的阻力。
如果我们想要修复我们的不稳定测试(并避免编写新的测试),我们就需要了解它们。
在谷歌,我们收集了大量测试数据:执行时间、测试类型、运行标志和消耗的资源。我研究了其中一些数据与不可靠测试之间的关系,并相信这项研究可以引导我们获得更好、更稳定的测试实践。
绝大多数情况下,测试用例越大(通过二进制大小、RAM使用或构建的库的数量来衡量),越有可能是不稳定的。
本文的其余部分将讨论我们的一些发现。
关于之间我们关于不稳定测试的讨论,可以参见 2016 年谷歌的文章 。
测试用例的大小 - 大型测试用例更不稳定
我们将测试分为三种大小:小型、中型和大型。每个测试都有一个大小,但这个标签的选择是主观的。工程师在最初编写测试用例时会选择“小、中、大”其中之一,而且这个标签并不总是随着测试用例的变化而更新。
对于某些测试用例来说,它已不再反映测试的大小。尽管如此,它还是有一定的预测价值。
在一周的时间里,0.5 % 的小型测试是不稳定的, 1.6 % 的中型测试是不稳定的, 14 % 的大测试是不稳定的。
从小到中,从中到大,不稳定性明显增加。但这仍然留下了很多问题。
这也就是我们从这三种尺码中所能知道的最多东西了。
测试用例越大,不稳定的可能性越高
我们收集了一些客观的大小度量:测试二进制大小和运行测试时使用的RAM「2」。对于这两个指标,我将测试分为大小相等的桶「3」,并计算了每个桶中测试的不稳定性百分比。以下数字是线性最佳拟合的r2值「4」。

我看到的测试(大部分)是提供通过/失败信号的密闭测试用例。在我们的测试用例中,二进制大小和 RAM 使用的相关性非常好,它们之间没有太大的差异。因此,这不仅是因为大型测试可能会出现问题,而且测试规模越大,不稳定的问题就越严重。
我已经在下面为这两个指标绘制了完整的测试集。不稳定性随着二进制尺寸的增加而增加「5」,但我们也看到在较大尺寸下,线性拟合残差增加「6」。
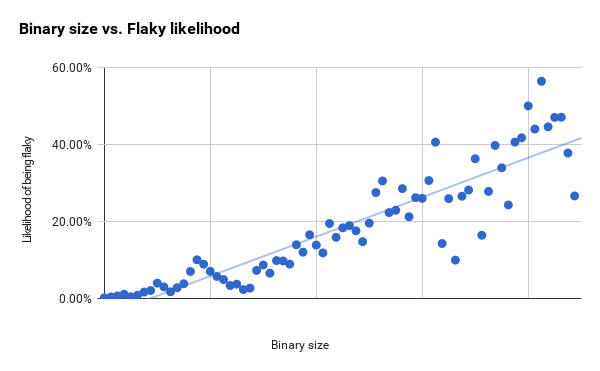
下面的RAM使用图表有一个更清晰的进展,只开始显示第一条和第二条垂直线之间的较大残差。
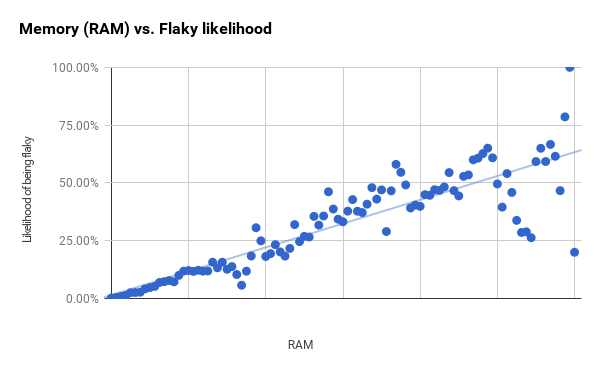
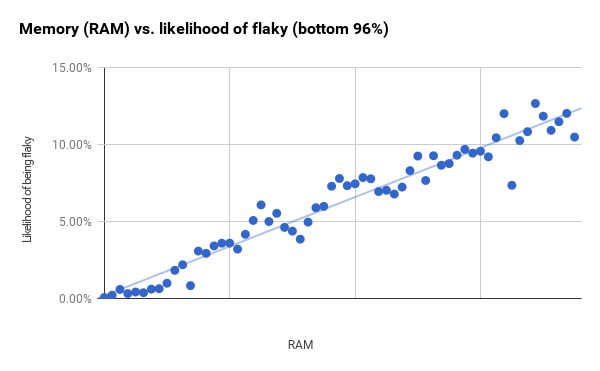
虽然分桶的大小不变,但每个桶中的测试用例次数不同。右边残差较大的点比左边的测试用例要少得多。如果我进行最小的 96 % 的测试(刚好超过第一条垂直线),然后缩小桶的大小,我会得到一个更强的相关性( r2 为 0.94 )。这可能表明,RAM 和二进制大小是比整体图表显示的更好的预测因素。
某些工具与更高的测试不稳定率相关
一些工具被指责是导致测试不可靠的原因。例如, WebDriver 测试用例 (无论是用 Java, Python, 或是 JavaScript 编写) 都不稳定「7」。对于我们常用的一些测试工具,我确定了使用该工具编写的所有测试用例中不可靠的百分比。值得注意的是,所有这些工具都倾向于用在我们的大型测试上。下面这些工具并不是我们所有测试工具的详尽列表,它代表了我们总体测试用例的三分之一。其余的测试使用不太常见的工具,或者没有易于识别的工具。
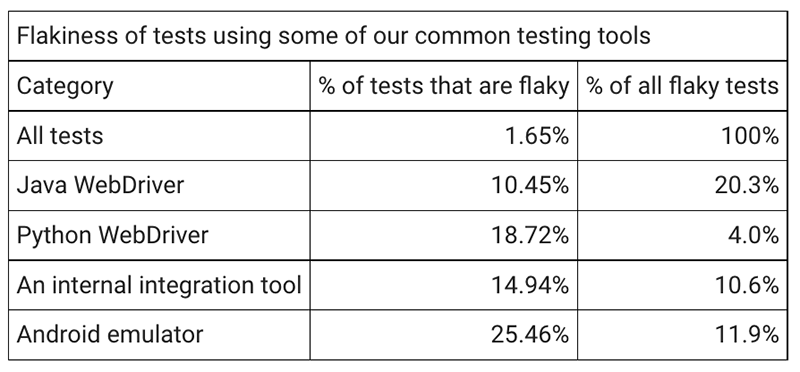
所有这些工具写的测试用例,其不稳定性都高于平均水平。考虑到我们五分之一的不稳定测试是 Java WebDriver 的测试用例,就可以理解,为什么我们的工程师抱怨它了。但相关性并不是因果关系,鉴于我们上一节的结果,可能有其他原因导致不稳定率增加。
测试用例的大小比所使用的工具更可预期
我们可以结合工具选择和测试大小,来确定哪个更为重要。
对于上面的每个工具,我都隔离了使用该工具的测试用例,并根据内存使用率( RAM )和二进制大小对这些测试用例进行了调整,这与我之前的方法类似。
我计算了最佳拟合线,以及它与数据( r2 )的相关性。然后,我计算了在最小的桶「8」(这已经是我们所有测试的第 48 个百分位)以及使用的 RAM 的第 90 个和第95个百分位上,测试用例出现不稳定性的预测可能性。
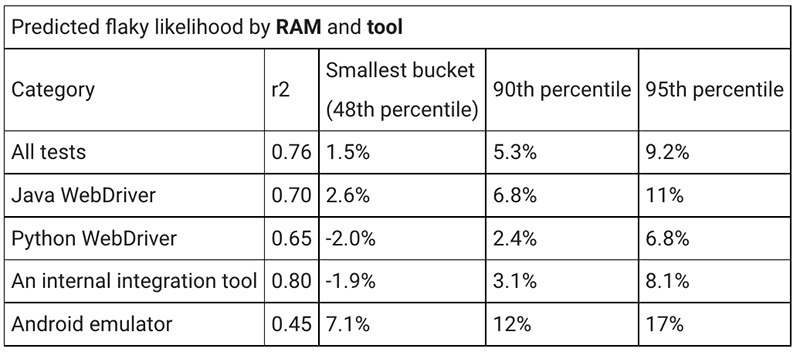
此表显示了 RAM 的这些计算结果。对于 Android emulator 以外的其他工具,这种相关性更强。如果我们忽略该工具,类似 RAM 使用的工具之间的相关性差异约为 4~5 % 。从最小测试到第 95 百分位测试的差异为 8~10 % 。这是这项研究最有用的结果之一:工具有一定的影响,但 RAM 的使用导致了不稳定性的较大偏差。
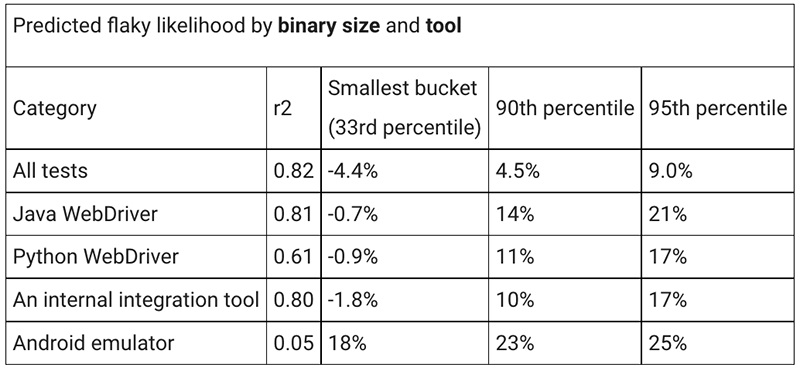
在 Android 模拟器测试中,二进制大小和不稳定性之间几乎没有相关性。对于其他工具,您可以看到,与 RAM 相比,小型测试和大型测试之间,可预测不稳定变化的相关性更大;高达 12 % 的分数。但你也会看到从最小尺寸到最大尺寸的更大差异;最大值为 22 % 。这与我们在使用 RAM 时看到的情况类似,也是本研究的另一个最有用的结果:二进制大小比您使用的工具在不稳定性方面的偏差更大。
结论
工程师选定的测试尺寸与不稳定性相关,但在谷歌内部,没有足够的测试用例大小的选项是特别有用。
客观测量的测试二进制大小和 RAM 与测试用例是否脆弱有很强的相关性。这是一个连续函数,而不是阶跃函数。一个阶跃函数会有突然的跳跃,并可能表明我们正在从一种测试类型过渡到另一种测试类型(例如,从单元测试过渡到系统测试,或从系统测试过渡到集成测试)。
使用特定工具编写的测试显示出更高的不稳定性。但这在很大程度上可以用这些测试用例的规模通常更大来解释。工具本身似乎对这种差异的贡献很小。
在决定编写大型测试之前,我们需要更加小心。想想你在测试什么代码,针对它的最小型测试例是什么样子的。
在编写大型测试时,我们需要小心。如果没有额外的努力来防止不稳定,你很可能会需要维护不稳定测试。
注解
- 如果一个测试在一周内至少进行了一次不稳定,那么它就是不稳定的。 2.我还考虑了为创建测试而构建的库的数量。在 1 % 的测试样本中,二进制大小( 0.39 )和RAM使用( 0.34 )的相关性强于库数( 0.27 )。我只研究了二进制大小和 RAM 的使用。
- 我的目标是每个维度大约100桶。
- r2 测量最佳拟合线与数据的匹配程度。值为 1 表示该行与数据完全匹配。
- 有两个有趣的区域,点实际上会反转向上的坡度。第一个从第一条垂直线的一半开始,持续几个数据点,第二个从第一条垂直线之前的右侧到之后的右侧。这里的样本量足够大,不太可能只是随机噪声。在这些点周围有大量的测试,这些测试比我只考虑二进制大小时所预期的要复杂得多。这是一个进一步学习的机会。
- 距观测点和最佳拟合线的距离。
- 其他网络测试工具也会受到指责,但 WebDriver 是我们最常用的工具。
- 最小桶的某些预测不稳定百分比最终为负值。虽然我们不可能有百分之负的测试是不可靠的,但使用这种类型的预测是可能的结果。