| 2017-04-04
生产环境是唯一的,无法复制
这是我们重要变某的第三部分,也是最后一部分。正如你见过的,我们减少了对在实验室内做功能测试的依赖,转而使用单元测试。 该策略的另一方面是更多地依赖生产环境中的测试。 当谈到云服务时,没有哪个环境能与生产环境保持一致。
在实验室中是很难复制生产环境的广度和多样性的。而且,客户的实际流量负载也很难模拟。另外,生产环境在不断变化, 它永远不会恒定。 即使应用程序没有变化,其内部的所有内容也在不断变化。我们所依赖的基础架构也在不断变化。因此,在过去的一段时间,我们才开始在生产环境上做越来越多的工作了。
我们做了什么
我们使用 TIP(生产环境测试) 这一术语时,我们指的是两件事:一套保护生产环境的实践,和另一套验证不断变化的生产环境的健康和质量的实践。
为了保护生产环境,我们以渐进和可控的方式发布代码变更。 这是通过带有功能开关支持的灰度部署模式实现的。关于功能开关(feature flags 参见下面链接)
feature flags——https://docs.microsoft.com/en-us/azure/devops/learn/devops-at-microsoft/progressive-experimentation-feature-flags
遥测(Telemetry)是指真实的测试数据; 它是真实客户负载量的测试结果。我们会观察很多内容,例如故障,异常,性能指标,安全事件等。遥测还能帮助我们检测异常。这些是在生产环境中运行的测试。它们是测试分类中的L3测试。这些测试是以生产环境的测试帐户来运行的。
故障注入和混沌工程
做故障注入和混沌工程,以了解系统在出现故障后的行为。这样做是为了验证我们已经实现的弹性机制是否真的生效和有效。我们还想验证某个子系统中产生的故障是否会被限定在该子系统内,而不会级联扩散成为整个产品的主要故障。如果没有故障注入,直到发生下一事件这时,我们才能证明我们之前对该类事件的修复工作是有效的。故障注入还能帮助我们为现场工程师(我们的“ DRI”)创建更切合实际的培训演练,并为处理实际事件做好更充分的准备。(关于弹性机制参见下面链接)
弹性机制:https://docs.microsoft.com/en-us/azure/devops/learn/devops-at-microsoft/patterns-resiliency-cloud
对断路器(Circuit Breaker)进行故障测试
下面我们在故障注入的帮助下在生产环境中进行测试的示例。 断路器很难在生产环境之外进行验证。 对于断路器,我们对两个问题感兴趣:
- 当断路器打开时,回退生效了吗?我们用单元测试验证它是起作用的,但是能在生产环境中起作用吗?我们使用故障注入的方式来强制断路器断开并观察回退行为。
- 当需要断路器断开时,它是否真的断开了?是否配置了正确的灵敏度阈值? 我们使用故障注入方式来强制等待时间,并断开与依赖关系的连接,观察断路器的响应能力。 它需要多长时间才能打开?
示例: 在Redis Cache上测试断路器
让我们通过Redis断路器来看一下这个过程。 Redis是产品中的非关键依赖项。 它是一个分布式缓存,这意味着如果它关闭了话,系统应该能够继续正常工作,调用应访问缓存的源头。如果Redis发生故障,则断路器应断开,并切换到原来的源上面。 这就是我们要检验的假设。
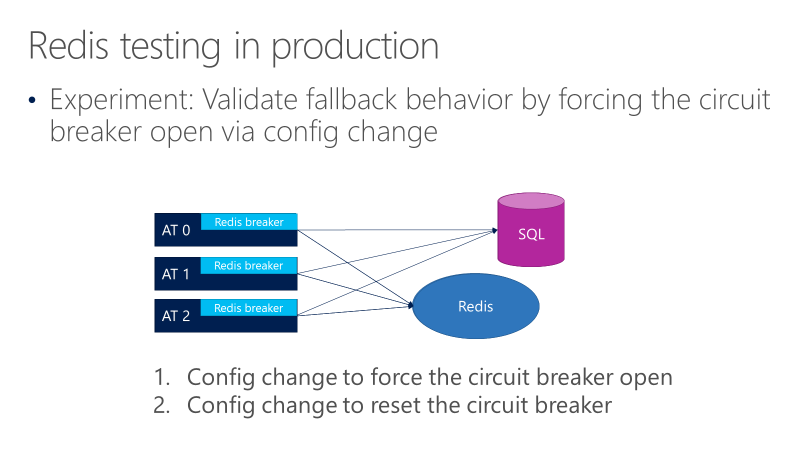
在上图中,我们有三个AT,断路器位于Redis的呼叫之前。 我们要确保断路器断开时,调用转到SQL。 该测试通过更改配置来强制断路器打开,以查看该调用是否会转向SQL。然后另一个测试检查相反的配置更改,即:合上断路器后,看到该调用返回到Redis。
此测试可验证断路器断开时回退行为是否有效,但不会验证断路器设置的配置。 断路器会在需要时打开吗?为了测试该问题,我们需要模拟实际故障。
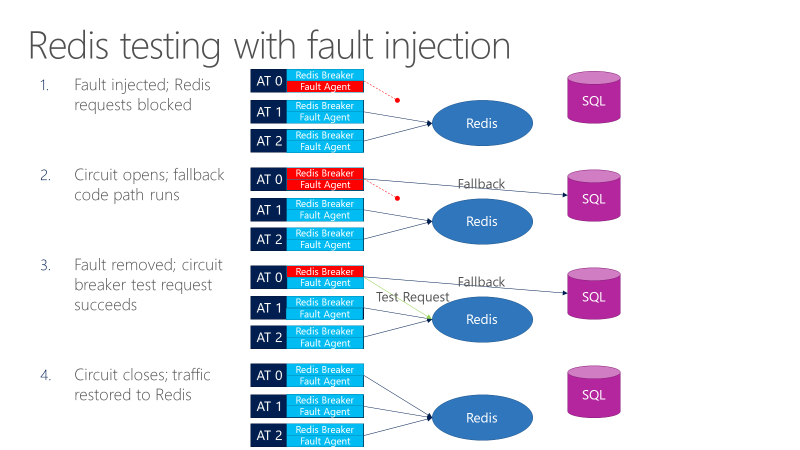
这是故障注入起作用的地方。 通过故障代理,我们可以在调用Redis的位置来引入故障。 故障注入器阻止了Redis请求,断路器断开,我们可以观察到故障恢复有效。现在我们可以消除故障,这样,断路器将向Redis发送测试请求。如果测试请求通过,则调用就恢复到Redis上。我们能够测试断路器的灵敏度,阈值是太高还是太低,或者是否存在其他系统超时会干扰断路器的行为。
在此示例中,如果断路器没有按预期方式打开或关闭,则可能会导致现场发生事故。如果没有故障注入测试,就无法断路器对进行测试,因为很难在实验室中进行这类测试。
从故障注入中学习到的
做混沌工程应该先在您的金丝雀环境中进行。对我们来说,它是第一个灰度梯度。我们自己团队日常所用的工程支撑系统也在这个金丝雀上运行着。如果金丝雀环境一旦出现故障,那么我们只会影响自己。所以,我们不会伤害客户。
您想让这种故障注入实验自动化,因为它们是成本很高的测试,并且系统总是在变化。您也可以在找到更多信息。
业务持续和故障恢复
故障测试的另一种形式是故障转移测试。 我们为所有服务和子系统制定了故障转移计划。 该计划包括几件事。 首先,如果服务中断,我们需要清楚地了解业务影响。 其次,我们需要根据平台,技术和人员来映射所有依赖关系,并设计业务接续和故障恢复计划。 第三,我们需要灾难恢复程序的正式文档。 最后,我们需要定期执行故障恢复演练。
微服务兼容性
我们到目前(2017年)拥有30多个微服务,而且都是独立部署的。现在我们有一个服务兼容性检测套件,我们把其作为滚动CI的一部分来执行。
但是,随着微服务的泛滥,以及众多潜在的兼容性组合,这种情况变得越来越复杂。 所以,我们依靠生产系统进行一些兼容性测试。L3测试承担了我们这个任务。基本思想是这样。
假设您有三个服务,S1,S2,S3。它们的版本为2.0。我们现在将S1更新为v3,并希望确保它可以与其他服务的v2兼容。L3测试是我们在生产环境中在测试帐户上运行的测试用例,并预先引用下一灰度级别的服务。 每个服务都有一个预部署环境。我们向前引用金丝雀环境来运行该服务的L3。测试通过后,我们会将该服务提升到金丝雀。 然后,随着通过后续灰度的服务提升,一直持续该过程。
关键要点
聚焦于构建一个快速和可靠的质量信号
如果只有一个要求,那就是构建一个快速和可靠的质量信号。这个信号是你的团队可以信任的,无论是DevBox,还是在主干,还是Release分支上。它让工程师有信心进行变更,因为他们知道系统会帮助他发现错误,而且它会尽快发现,以便工程师采取措施。对质量信号的信任使他们能够推动更多的变化。如果信号太慢或不可靠,就会阻杀整个流水线。脆弱性让测试自动化毫无用处,更糟糕的是,源于一个地方的脆弱性会蔓延到整个流水线。左移不仅是一个口号,还可以翻转测试金字塔。 我们已经做到了–如此处所示。
合体工程师驱动更好的担责文化
我们认为,合体工程师是驱动更好的担责文化的比较好的模型。端到端的责任感驱动正确的行为。减少了任务交接让团队敏捷起来。这并不是说,专业化不重要了。它仍旧是有价值的,只是不必为它专门地组织一个专职团队。
发布到生产环境才算完成50%
发布到生产环境只是完成了一半。另一半是确保在真实的负载下的质量。找不到与生产环境一样的环境了。这个生产环境一直在变,所以,在生产环境上的测试永远没有结束的时候,这些工作包括监控,故障注入,故障转移测试,以及其它形式。
原文链接:
文字:https://docs.microsoft.com/en-us/azure/devops/learn/devops-at-microsoft/shift-right-test-production
视频:https://bit.ly/2Xbds8f