| 2021-01-14
MTTR、MTBF 和 MTTF 等指标对于任何具有服务依赖性的组织都是必不可少的。只有跟踪这些关键KPI,企业才能最大限度地延长正常运行时间,并将中断保持在最低限度。
维护服务的可靠性是 SRE 工程师每天面临的一个挑战。虽然故障度量在这种情况下非常有用,但要有效地使用它们,就要知道它们背后隐藏着什么含义,如何区分它们,如何计算它们,以及它们对您有何影响。
故障度量简介
即使是最高效的运维团队也会遇到服务或设备故障。这就是为什么为他们做计划是至关重要的。
那么,服务故障是什么样子的?
故障以不同程度存在(例如部分或全部故障),但在最基本的术语中,故障仅仅意味着系统、组件或设备不能再产生特定的预期结果。
所以,即使一个服务仍在运行,并提供服务,如果没有达到预期的数量和质量,那它就是出故障了。
正确地管理故障,可以帮助显著地减少故障的负面影响。为了有效地管理故障,应该监控几个关键指标。了解这些指标可以消除猜测,并为 SRE 工程师提供做出明智决策所需的硬数据。
那么,应跟踪哪些故障指标?有三个指标是可以跨行业应用的,它们是 MTTR、MTBF 和 MTTF 。下面,我们讨论这些缩写词的含义,以及如何使用它们来改进。
但在此之前,我们需要讨论一件经常被忽视的事情——故障度量的前提是拥有可靠数据的重要性。
可靠数据的重要性
要在设备故障中进行数据支持的改进,关键是要收集正确的数据并使数据准确。
先进的故障统计需要大量有意义的数据。正如我们将在下面的故障度量计算中所示,必须收集以下输入作为故障维护历史的一部分:
- 故障维护工时
- 故障次数
- 运行时间(例如:根据每周总预期运行小时数-总设备停机时间计算)
尽管记录每次的故障维护数据可能很乏味,但这是改进操作的一个重要部分。下图是 MTTR 和 MTBF 的计算示例。
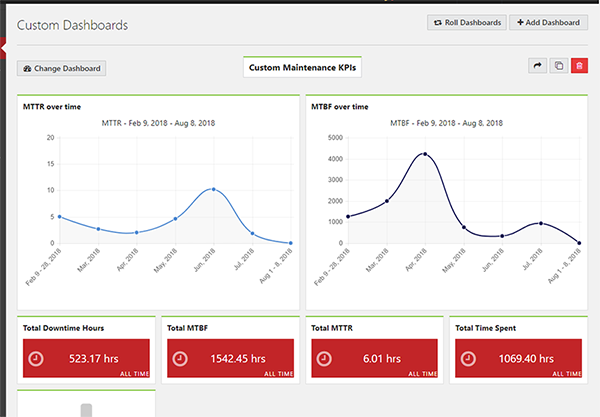
收集的数据不准确会引起很多问题。
如果数据丢失或不准确,故障度量将无法为改进操作的决策提供信息。更糟糕的是,如果你不知道数据是不可靠的,你最终可能会做出适得其反和有害的经营决策。
什么是 MTTR ?
MTTR 就是 Mean Time To Repair 的缩写,名为 平均修复时间,它是指修复系统并将其恢复到完整功能所需的时间量。
修复开始时,MTTR时钟开始滴答作响,直到恢复操作为止。这包括修复时间、测试时间和恢复正常工作状态所需要的时间周期。
如何计算 MTTR ?
要计算MTTR,就是将总维护时间除以给定时间段内维护操作的总数。

想象一下,一个水泵在一个工作日内出现三次故障。修复每一个故障所花的时间总共是一个小时。在这种情况下,MTTR 将为 1小时/3 = 20分钟。
需要注意的几点:
通常,每个失败实例的严重性都会有所不同。因此,虽然有些事故需要几天时间才能修复,但其他事故可能只需要几分钟就能修复。因此,MTTR给出了期望值的平均值。
为了获得可靠的结果,每次维修都必须由经过培训的合格人员进行,这些人员必须遵循明确的程序。 每一个高效的维护系统都需要研究如何尽可能地降低MTTR。这可以通过几种不同的方式来实现。 一种方法是通过跟踪备件和库存水平(从而在采购零件时节省停机时间)。
另一种方法是实施前瞻性维护策略,如预测性维护。预测性维护(PdM)将使您能够更好地监测在役设备的状况,并通过使用直接安装在容易发生故障的部件上的状态监测传感器更准确地预测潜在故障。 这些传感器可以提前提醒他们什么时候会发生故障。此时,修复不再是被动的,而是预测性的,因为经理有足够的时间安排执行作业所需的所有资源。
为什么 MTTR 有用?
花费太长时间来修复系统或设备是不可取的,因为它会对业务结果产生非常不愉快的影响。对于那些对失败特别敏感的服务来说,情况尤其如此。它常常导致生产环境停工、收入损失等等。
了解 MTTR 对于任何组织来说都是一个重要的工具,因为它告诉你如何有效地响应和修复生产中的问题。大多数组织都希望通过内部维护团队(由必要的资源、工具及软件支持)来降低 MTTR。
平均修复时间 vs 平均恢复时间
首字母缩略词 “ MTTR ” 有两个最常用的含义,一个是“平均修复时间”(如上所述),另一个是“平均恢复时间”
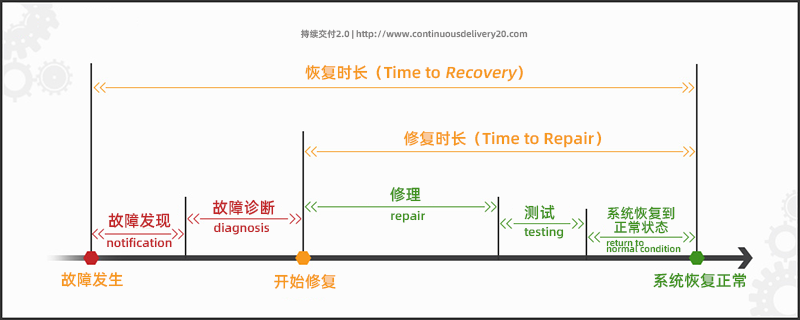
平均恢复时间(Mean Time To Recovery)是指从首次发现故障点到恢复运行点之间的时间。因此,除了维修时间、测试周期和恢复正常工作状态外,我们还要捕获故障通知时间和诊断时间。
尽管这两个术语通常可以互换使用,但在服务级别协议(SLA)和维护合同中,区分的必要性变得非常重要。
因此,这类合同的所有当事方都需要就它们究竟在衡量什么达成一致。
什么是平均无故障时间 (MTBF)?
第二个故障度量是平均无故障时间 (Mean Time Between Failures, 简称 MTBF )。它是指在正常运行过程中,系统从一个先前故障到下一个故障之间经过的预期时间。简单地说,MTBF可以帮助您预测系统在下一次计划外故障发生之前可以运行多长时间。
对在某个时刻发生故障的预期(预测)是MTBF的一个重要部分。
术语 MTBF 用于未预见故障,但不考虑因例行定期维护或例行预防性升级而停机的服务。更确切地说,它捕获了由于设计条件导致的故障,这些设计条件使得在修复系统之前必须使系统停止运行。
因此,MTTR 衡量可用性,MTBF衡量可用性和可靠性。MTBF值越高,系统在发生故障前运行的时间就越长。
如何计算 MTBF?
从数学上讲,从一个故障到下一个故障的时间间隔可以用运行时间之和除以故障次数来计算。

看看我们在上面 MTTR 中提到的水泵的例子。在10小时的预期运行时间之外,它运行了9个小时,并且三次故障消耗了一小时的时长。因此,MTBF=9小时/3=3小时。
从上面的例子可以看出,MTBF的计算中不包括恢复时间。
除了前面提到的设计条件外,其他常见因素往往会影响现场系统的平均无故障时间。
其中一个主要因素是人与人之间的互动。例如,MTBF 低可能表示,运营商处理不当,也可能表示过去的工程师工作执行不力。
为什么 MTBF 有用?
平均无故障时间(MTBF)是可靠性工程中的一个重要标志,它起源于航空工业,在航空工业中,飞机故障会导致人员死亡。
对于飞机、安全设备和发电机等关键资产,平均无故障时间是衡量其预期性能的重要指标。因此,制造商使用它作为一个可量化的可靠性指标,并在许多产品的设计和生产阶段作为一个必不可少的工具。它现在常用于机械和电子系统设计、工厂安全操作、产品采购等。
即使是购买某个特定品牌的汽车或电脑这样的日常决定,也会受到购买者对MTBF高于下一个品牌的产品的渴望的影响。
虽然 MTBF 不考虑计划性维护,但它仍然可以用于计算预防性更换的检查频率。
如果已知某项资产在下一次故障前可能会运行一定的小时数,那么引入诸如润滑或重新校准之类的预防措施可以帮助将故障降至最低,并延长资产的正常运行时间。
什么是平均失效时间(MTTF)?
平均失效时间(MTTF)是衡量不可修复系统的可靠性的一个非常基本的指标。它表示一个系统预计持续运行直到失败的时长。
MTTF 是我们通常所说的任何产品或设备的寿命。它的价值是通过在一个较长的时期内观察大量相同种类的系统或物件,并查看它们的平均失效时间来计算的。

在制造业中,MTTF 是评价产品可靠性的常用指标之一。
然而,由于 MTTF 和 MTBF 在定义上有一定的相似性,在区分MTTF和MTBF时仍存在许多混淆。
好消息是,记住 MTBF 仅用于可恢复系统时,MTTF 用于不可修复物品时,这一点很容易解决。
当使用 MTTF 作为故障度量时,那对资产的修复就不是一个选择了,只能更换。
如何计算 MTTF ?
MTTF的计算方法是总运行小时数除以被跟踪的项目总数。

假设我们测试了三个相同的水泵,并且每个水泵都运行到发生一次故障。第一个泵在 8 小时后出现故障,第二个泵在 10 小时后出现故障,第三个泵在 12 小时后出现故障。
那么,它的 MTTF为(8+10+12)/3=10小时。
这将使我们得出结论,这种特殊类型和型号的泵平均每 10 小时需要更换一次。
提高 MTTF 的唯一可靠方法是寻找由更耐用的材料制成的更高质量的产品。
为什么MTTF有用?
MTTF是一个重要的指标,用于估计不可修复产品的寿命。这些产品的常见例子从汽车的风扇皮带到我们家和办公室的灯泡。
尤其是,MTTF 对于可靠性工程师来说非常重要,因为他们需要估计一个组件作为一个更大的设备的一部分可以使用多长时间。当整个业务流程对相关设备的故障非常敏感时,尤其如此。
在这种情况下,MTTF 成为设备可靠性的主要指标,旨在最大限度地延长资产寿命。更短的 MTTF 意味着更频繁的停机和中断。
最后的想法
SRE工程师的首要任务之一是确保系统的最大可用性,以及保持系统的安全和高效运行。了解故障度量的计算和使用将使 SRE 专业人员能够更准确地确定关键资产最有可能发生故障的时间。
根据这样度量以及发现,他们可以着手制定更好的管理策略,并改进其整体维护流程。
通过计算故障度量和基于这些结果的计划维护,还可以减少组织对应激式维护的依赖性,从而支持计划(预计)维护,这正是他们激发业务增长所需要的。
原文链接: