| 2022-03-01
History
我的团队长期以来的传统是每年组织两次黑客大会( hackathons )。在黑客大会( hackathons )之前的几周,团队会收集和集思广益项目的想法,从改进测试基础设施或现有流程,到尝试他们已经想了一段时间的疯狂想法。就在 hackathon之 前,团队在 coolness-impact 上对累积的这些想法进行评分:一个项目听起来有多有趣,它可能有多大影响;虽然影响力很重要,但对黑客来说,乐趣是必须的。然后,对某些提议的项目感到兴奋的工程师就可以组建团队。即使在 2013 年那样寒冷的冬天,对我们的热情也没有什么影响,那里有太多冷静而疯狂的想法,其中之一就是这个突异测试的原型。
对于那些不熟悉它的人来说,变异测试是一种评估测试质量的方法,通过向代码中注入错误,并查看测试是否检测到错误。测试捕获的注入错误越多,效果越好。下面是一个例子:
Negating the if condition.

如果测试失败,我们就说它杀死了突变体,如果没有测试失败,我们就说突变体还活着。
在 HACKASTON 结束后,我们为 C++ 和 Python 写了变异测试工具 mutagenesis ,原型诞生了:它是一个 shell 脚本,它评估在 DIFF( PR )中生成的变异体,并在这个 DIFF 中的文件里报告还活着的突变体。在那以后,直到一年之后,我才用 20% 时间来继续开发它。当时我不知道什么是变异测试,所以我研究并阅读了关于这个主题的论文,收集了很多关于我应该关注什么的想法。
从原型到发布
我很快意识到,在 hackathon 上,同事们并没有计算突变分数,只是列举了活的突变体,而没有计算通过测试检测到的突变体的比率,而这是研究文献中的一个重要指标,也是评估测试质量的圣杯。我第一次接触突变体只是在变异代码本身上运行这个工具,并试图理解报告。而我马上就不知所措了:在执行了很长一段时间后,我发现,我在少数几个文件中要面对成千上万的变异点。我自己试着看了几遍,但没有多久,我就累了,继续我的主要工作项目,也就是谷歌购物项目。在接下来的几个月里,我远离了我的 20% 项目,但我一直在思考它,让我的同事和朋友一起想办法,如何能让变异测试为我们工作。经过几个月的头脑风暴和讨论,在最初的 hackathon 项目将近一年后,我准备设计变异测试服务。
我面临两大问题。首先,我虽然可以逼着自己一个个查看所有的变异处,也许可以发现一两个有用的点,但我不能逼着其他人这么做。其次,大量的变异点其实很差劲。下面是一些例子:
是的,这些测试没有检测到这些变异点,我们无论如何也不会想要这样的测试。它们中的很多只能产生脆弱的、变更检测式的测试用例。我们后来决定称它们为非生产可用的突变体:为这些突变体编写测试,会使测试套件的质量变得更糟,而不是更好。
我意识到我需要抑制这些种类的变异,否则,没有人会使用变异测试,包括我自己。大多数突变体都没有什么用处,这会浪费开发人员的注意力。我应该创造一个更好的工具。我开始尝试各种启发式方法,通过查看结果报告,限制我能发现的无效突变体。我在AST(抽象语法树)匹配规则中对启发式进行编码,并将包含无效突变体的AST节点称为无用的(arid)节点。起初,系统中仅设定了少量的几条规则,但这也足以让我相信,我的同事会尝试一下。
另一个大问题是突变体的数量。一行代码中有五个或者更多,而一个文件中有数百个,如何把它们显示出来,就是一个挑战。而且,即使我能做到这一点,可能也没人会浏览它们。我很快意识到,本来不应该是这样做:我花了很多时间研究突变体,尽管某些突变体的确给我指出我的测试套件中有一个漏洞,但大多数突变体都是无用的,其中很多是多余的,尤其是在同一行的突变体。我并不需要通过对所有可能的操作符组合进行变异,来说明我对该条件的测试是不够的;一个就够。于是,我决定:一行代码中最多报告一个突变。这是一个快速而简单的决定。如果你曾经使用过代码评审系统,你就会知道,太多的代码变更会让评审变得嘈杂和困难。另一个原因是,计算所有突变体的计算成本高得令人望而却步。我称之为限制驱动的开发。
Of course, the idea was to report live mutants during Code review. Code review is the perfect time in the engineering process to surface useful findings about the code being changed, and integrating into the existing developer process has the highest chance that the developers will take action. This seemed like the most normal thing in the world: we had hundreds of analyzers and all engineers were used to receiving findings from various analyses of their code. It took an outsider to point out that this was a strange approach: mutation testing was classically run on the whole program and the mutation score calculated and used as guidance.
当然,我只想在在代码评审期间显现这样活跃的突变体。在整个开发过程中,代码评审是用来展示变更代码的最佳时机,将我的变异测试报告放在其中,是最有可能让开发人员采取行动的时机。这似乎是世界上最正常的事情:我们有数百个分析器,所有工程师都习惯于从各种代码分析中获得结果。你可能觉得奇怪,因为突变测试通常是在整个程序之上运行的,并且会计算变异分数,以用作指导。
下面是变异测试结果在代码评审时的查看页面:

谷歌的突变测试是一个动态的代码变化分析器,它把变异测试在代码中发现的问题展现到代码评审页面。在基础设施方面,它由三个主要部分组成:更改侦听器(change listener)、分析器(analyzer)和许多诱变服务器(mutagenesis servers),即:每种语言一个服务器。

代码审查期间的每个事件都是使用发布者-订阅者模式发布的,任何对某个事件感兴趣的一方都可以监听这些事件,并做出反应。当变更被发送到代码评审时,会发生很多事情:运行linter、评估自动测试、计算覆盖率,以及为变异测试的用户生成和评估突变。监听来自代码审查系统的所有事件时,侦听器会安排在分析器上运行一次变异测试。
分析器要做的第一件事是:获取相关补丁的代码覆盖率结果;分析器从中可以推断出哪些测试覆盖了哪些源代码。这是一条非常有用的信息,因为只运行那些能够找到突变体的最小测试集是至关重要的;如果我们运行所有与该项目相关的测试,或者覆盖该项目,那么,计算成本将高得令人望而却步。
接下来,对于补丁中每个文件中的每个覆盖行,要求该语言的诱变服务器生成一个突变体。突变服务器解析文件,遍历其AST,并按请求的顺序(根据突变上下文)应用突变子,忽略干旱节点、未覆盖线中的节点以及不受拟议补丁影响的线中的节点。
当分析器找到所有突变体时,它会逐一将它们打补丁到代码上,然后并行地评估每个突变体的所有测试。对于所有测试都通过的突变体,分析器会向代码作者和审阅者展示出来发现。
2015年末,我为谷歌购物工程生产力团队启动了变异测试。大约有十五位同事在他们的代码审查中发现了突变体,这是一个坎坷的开始。正如您在上面的代码审查屏幕截图上看到的,每个发现都有两个按钮:“请修复”和“该信息无用”。审阅者可以指导代码作者修复某些发现(例如,Clangtiy 发现可能会指出某个对象被不必要地复制,并建议使用引用,或者变异测试可能会指出某代码没有经过良好测试)。作者和所有评论者可以向发现/分析器的作者反馈他们的发现没有用处。这是一个有价值的信息来源,我利用了它。对于每一个被认为没有用的突变体,我都会检查它,看看是否可以从中进行归纳,并为我的arid节点启发法添加一条新规则。慢慢地,我收集了几百种启发法,其中许多普遍适用,但也有许多与内部框架有关,比如监控框架。我越来越注意到,仅仅将节点标记为arid并抑制其中的突变体是不够的;需要一个更强大的机制来进一步降低这种噪音。看看下面这些激励性的例子:
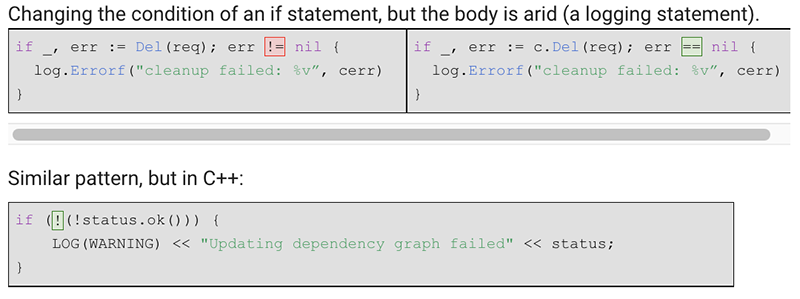
我设定了一个传递规则:如果我认为AST节点是无用( arid )的,或者,假如它是一个复合语句,并且它的所有主体也是无用 (arid)的,那么它就是无用( arid )的。回想起来,这是有道理的,但这需要人工查看一下变异结果中那些无效突变体的例子才能结晶。因为 Log 语句是无用( arid )的,而整个 if 子句的主体也是无用( arid )的,因此,if 子句本身及它的条件子句也是无用( arid )。
在2015的夏天,我的实习生,MaG.Grasa SalaWa,和我对 C++、GO、Python 和 java 实现了突变,并且具有传递性的节点检测和堆栈,最多每行一个突变,每个文件有7个,我们称之为V1.0并启动。
突变测试一直是作为一个可选择项加入到我们的服务当中的,一开始只有少数用户(2016 年第一季度只有 93 个代码审查)。但随着时间的推移,到了2017年2月,它的用户数量增加到 2500 个,如今已达数万个。早期对于获得用户的反馈和进一步扩展 arid 节点启发法至关重要。在一开始,无效率约为 80 %,这已经是加了了一些启发式方法,并且限定了每行最多一个突变。随着时间的推移,我把它降到了 15 %左右。我一直认为,基于突变体的性质,将比率提高到 0 %是不可能的:有时,突变体会产生与原始行为相同的行为,而且无法完全避免。
通过移除缓存并始终重新计算来更改缓存查找,会产生功能等效的代码,而传统测试无法检测到这些代码。

我感到惊讶和高兴的是,我可以将无效率降低到 50 %以下。
Mutation Context
随着时间的推移,我增加了对更多语言的支持。2017年初,我实现了对 JavaScript 和 TypeScript 的支持,并在今年晚些时候增加了对 Dart 的支持。2018年,我增加了对 ZetaSQL 的支持。最后,在 2020 年初,我增加了对 Kotlin 的支持,因为它在 Android 世界越来越流行。
我记录了所有变种的各种数据:它们的存活率和请修正/不有用的比率。
性能最差的变异体是ABS(Absolute Value Mutator),它将表达式替换为 ±abs(expression),例如:

看看上面的这些例子,我不得不同意这个结论。因为对于这个变种的反馈大部分都是负面的,所以我很快就在所有语言中完全禁用了这一个突变体。
我很快注意到,SBR(语句块删除,Statement Block Removal)变异器是最常见的一种,它可以删除语句或整个块,这是有道理的:虽然变异逻辑或算术运算符需要代码中存在这样的运算符才能进行变异,但任何代码行都可以删除。然而,由代码删除所产生的突变体并没有最好的实用性或生产力。事实上,几乎所有其他的突变都产生了比 SBR 更高效的突变,这让我想到:并不是所有的代码都是一样重要的;包含 return 语句的 if 语句中的一个条件表达式与另一个位置中的条件表达式的重要程度是不一样的。
我由此产生了一个想法:基于上下文的变异子。对于每一行,我会对突变算子随机洗牌,然后逐个挑选,直到其中一个在该行生成一个突变。但这并不太理想,因为我知道有些操作符在某些情况下比其他操作符更有作用。我决定根据历史数据,选择一个最有可能产生存活突变的算子,而不是随机选择一个突变算子,该突变算子在报告时最有可能产生有效结果。我有数以百万计的变异体需要学习,我只需要定义代码片段之间的距离。当我在上下文中查看与父节点相似的 AST 时,我在上下文中查找与子节点相似的 AST ,最后在上下文中查找与子节点相似的 AST 。通过距离测算,在实习生马戈尔扎塔的帮助下,很容易地从历史上的变异体中找到最接近的 AST 上下文,并观察它们的命运,选择最好的一个。我根据它们的生产力排序了变异算子,并试图在节点中按这个顺序生成一个变异算子,因为很可能有些变异算子不适用于某段代码。
这是一个很大的进步。所有突变算子和编程语言的突变生存能力和有用性都显著提高。你可以在即将发表的论文中阅读更多关于这些发现的信息。
Fault Coupling
只有当我们为突变体编写的测试用例有价值时,突变测试才有价值。突变体与真正的 Bug 不同,它们比正常测试中发现的虫子要更简单一些。突变测试依赖于耦合假设:如果一个敏感到足以检测到突变的测试套件也敏感到足以检测到更复杂的真实缺陷,那么突变就与真实缺陷耦合。报告突变体并编写杀死它们的测试只有在它们与真正的bug结合时才有意义。
我本能地认为 Fault Coupling 是真实的,否则我根本就不会进行突变测试。我见过很多情况下,突变体指向错误;不过,我还是想验证这个假设,哪怕只是为了我们的代码库。我设计了一个实验:我会在一行中生成所有的突变体,以进行明确的 bug 修复更改。在修复 bug 的前后,我会检查,如果进行了突变测试,是否会在引入 bug 的变更中出现突变体,并有可能阻止它(即,在修复错误和添加新测试用例的变更中被杀死)。我在周末进行了一个多月的实验,因为我们没有资源在工作时间进行实验。虽然我通常在一行中生成一个突变体,为了测试 Fault Coupling 效应,我使用了经典的突变测试方法,生成了所有可能的突变体,同时仍然坚持 arid 节点抑制。总共执行了 3300 万个测试套件来测试数十万个突变体,最终得出结论,在大约 70 %的情况下,一个bug与一个突变体结合在一起。
当我在做这件事的时候,我也检验了我的直觉,即:每一个突变株是否足够。并发现绝大多数情况下是这样的:在超过 90 %的病例中,要么所有突变株都在一个株系中被杀死,要么没有。值得记住的是,我仍然在这个实验中应用了我的 arid 节点抑制启发法。很高兴终于证实了我的直觉。
我还研究了在一个项目上使用变异测试更长时间后,是否引起了开发人员行为的变化,我发现,随着开发人员接触到越来越多的突变体,使用变异测试的项目会随着时间的推移得到更多的测试用例。开发人员不仅编写了更多的测试用例,而且这些测试用例在杀死突变体方面更加有效:随着时间的推移,报告中的突变体越来越少。我也从个人经历中注意到了这一点:在编写单元测试时,我会看到自己在测试中走了一些弯路,并预见到了突变体。现在,我只是添加了缺失的测试用例,而不是在我的代码审查中面对一个变种,我现在很少看到变种,因为我已经学会了预测和抢占它们。 你可以在我们的ICSE论文中阅读更多关于这些发现的信息。
结论
自从 2013 年冬天的那场黑客大赛以来,我的这条路已经很长了。变异检测工作很有趣。它有它的挑战,我曾经想过将这一切都扔进下水道不管了,但我还是很高兴我坚持了下来。
该项目最有趣的部分是让变异测试扩展到如此大的代码库上,这需要重新定义问题,并使其适应工程师已经习惯的现有生态系统。另一个有趣的角度是向学术界学习,特别是戈登·弗雷泽(帕绍大学)和勒内·贾斯特(华盛顿大学)。
我想鼓励大家在你的项目中尝试一下开源变异测试工具,并进行一些适当的调整,这可能是一个很好的方法来保持你的软件有良好的测试。
发表时间:April 12, 2021
原文作者:Goran Petrovic
原文链接:Mutation Testing